The road to 100 billion records
At Intelligence X, we value quality over quantity. Our goal is continuous improvement, sustainability, and stability. As we cross the mark of 25 billion records with 100+ TB of storage, it is time to set sail for 100 billion records.
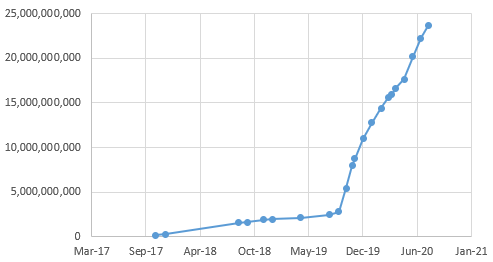
Counting records
A single record is an extracted selector (search term) like “test.com”. A search term might appear in one or multiple documents. Intelligence X is not just a search engine; it is also a data archive that stores copies of the actual search result (i.e. the original document) in its cache.
Therefore, each record has one or multiple documents linked. Any change of the dataset, documents, the indexing algorithm, or meta-data is not a simple operation. We have developed our own proprietary storing, indexing, and searching algorithms that allow us to scale infinitely into billions of records and Petabytes of data while maintaining a fast search & retrieval speed (within ms).
What keeps us from growing faster
There are multiple constraints that limit the amount of records and content that can be indexed:
- Cost related: Disk storage (HDDs and SSDs), processing power, network uplink
- Spam: Content that is repetitive or low-quality, taking up resources that could be used instead for quality content.
- Hard disk I/O operations per second (IOPS)
IOPS is the limiting factor when it comes to indexing the speed of new websites within a single bucket. The amount of single input/output operations (per disk) essentially limit how fast new websites (HTML copies) can be stored and processed for indexing.
Spam
Spam is a big reason why we don’t just flip the switch and crawl the whole public web as of right now. It is both a challenge on the darknet and the public web. Operators may create endless sub-pages, sub-domains, and register many spam domains. We previously published the blog post, “Combating spam websites from Tor”. A recent example of spam related to Tor hidden services:
https://twitter.com/_IntelligenceX/status/1297141706362687488
There is 0 value in spam content for Intelligence X and our customers so we blacklist and delete any content that we deem as spam. Here is the overview of active vs. inactive vs. spam onion domains; it reveals that there are more spam domains than active ones, highlighting the need and importance for spam detection algorithms:
https://twitter.com/_IntelligenceX/status/1297163393196068864
Another example on the public web is spam detected in our “Web: Germany” bucket: The domain “anki-overdrive-kaufen24.de” had 3,362,715 subdomains in our index – a typical example of endless auto-generated subdomains with a catch-all DNS record.
While developing spam detection algorithms may be a relatively easy task, operating such an algorithm on millions (or billions) of records makes it a delicate operation whenever the algorithm is changed.
Public Web: Flipping the switch soon
Our public web crawling started in October 2019 and is currently limited to these top-level domains per bucket:
- Germany DE, AT, LU, CH
- Russia: UA, KZ, RU
- International: COM
As we are gradually expanding our crawling operations, new TLDs to be indexed will be announced soon.
According to DomainTools, these are the TLDs with the most domains:
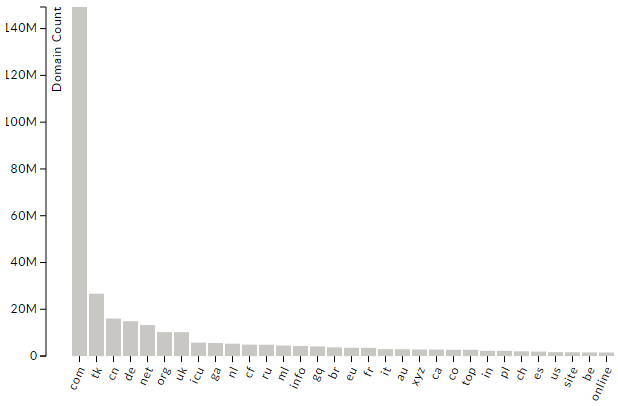
Screenshot: DomainTools
What’s next?
We are always looking to add new data sources and expanding the ones we already have. We are reviewing these new sources (in no particular order):
- Wikipedia
- IPFS
- Usenet
- Public FTPs
- Public SMB shares
- P2P filesharing protocols
- Document sharing services
The cool thing about adding new data sources is that any newly indexed data is available in real-time through the entire Intelligence X ecosystem: The main search intelx.io, the API, our phonebook.cz, and of course all integrations by 3rd party tools.