New Python API wrapper and Command Line Interface
We have teamed up with @zer0pwn to develop a completely rewritten Python API wrapper and Command Line Interface.
👉🏼 github.com/IntelligenceX/SDK/tree/master/Python
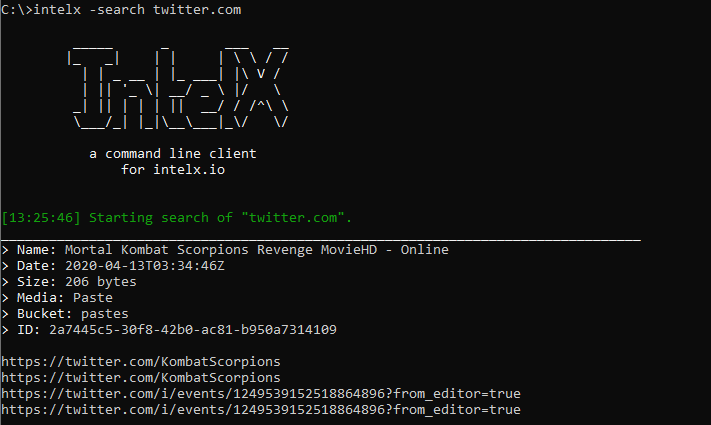
To install the command line tool run these commands (requires Python 3, tested against latest 3.8.2):
git clone https://github.com/IntelligenceX/SDK
pip3 install SDK/Python
In order to see all results, you should specify your API key via the -apikey [key] argument or put it into the INTELX_KEY environment variable. If you don’t specify one, it will use a default public key, which we may, however, disable in the upcoming weeks. You can get your API key here: intelx.io/account?tab=developer
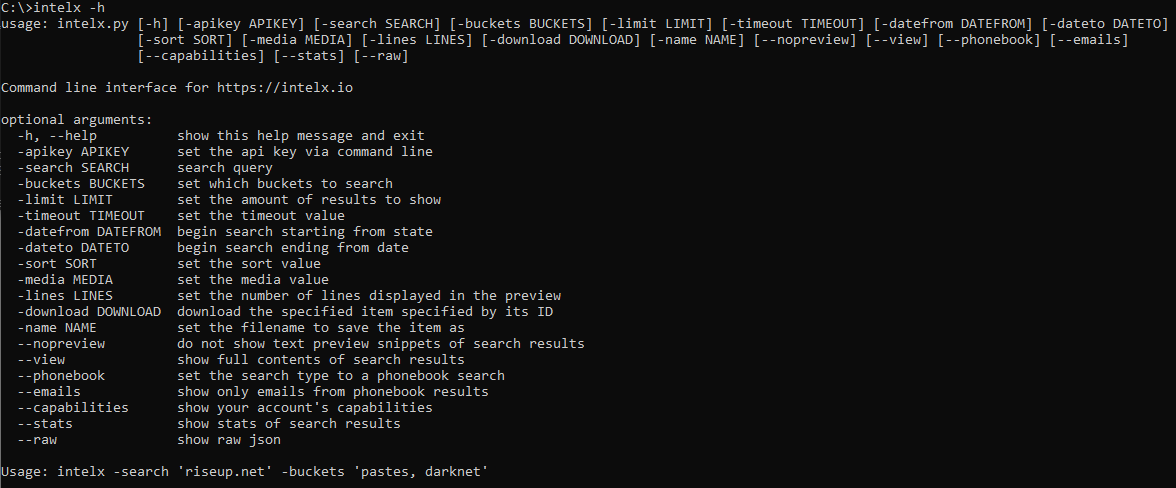
To see all available options use intelx -h:
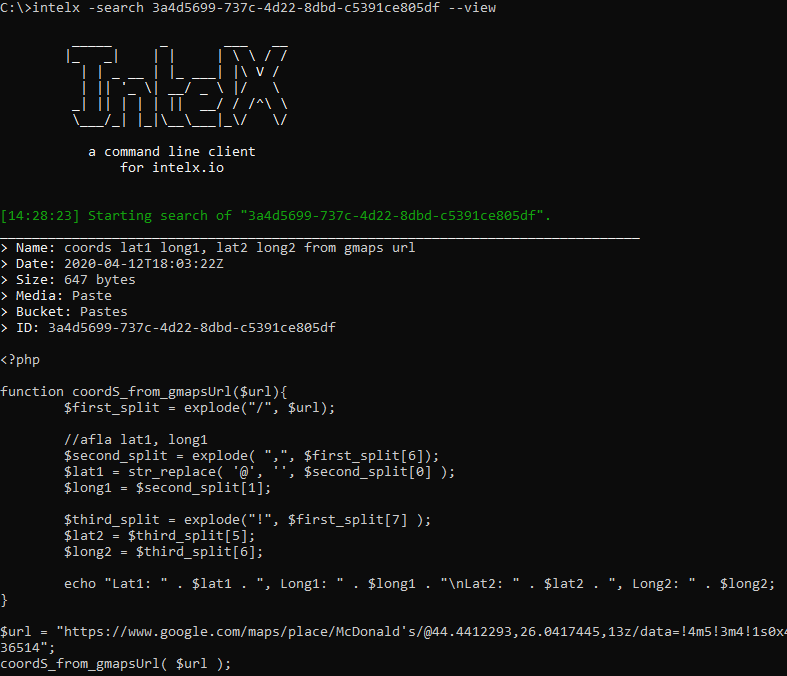
To view the data of an individual search result, specify its ID and use the --view parameter:
intelx -search 3a4d5699-737c-4d22-8dbd-c5391ce805df --view
We will continue to improve the SDK and push out announcements via this blog and our newsletter. Make sure to subscribe to the newsletter at intelx.io/account by clicking on the “Newsletter Settings” button.