Decoding the US Death Master File
“The Death Master File (DMF) is a computer database file made available by the United States Social Security Administration since 1980″ according to Wikipedia. It is available here ladmf.ntis.gov but costs $2,930.00 anually.
The file has since been posted on the internet for free, including here:
- ssdmf.info/download.html November 30, 2011
- cancelthesefunerals.com/ May 31, 2013
- archive.org/details/DeathMasterFile May 31, 2013
This file can be useful for OSINT (Open Source Intelligence) discovery as it contains millions of US SSNs (Social Security Numbers), so we have decided to add it to our search index.
Here is the file indexed in our search engine: intelx.io/?did=fd36a1b3-35ff-429b-8c19-e6a4e229ffb9
Format
The Death Master File is a text file with 100 characters per line each representing one record. This is the official format specification according to dmf.ntis.gov/recordlayout.pdf:
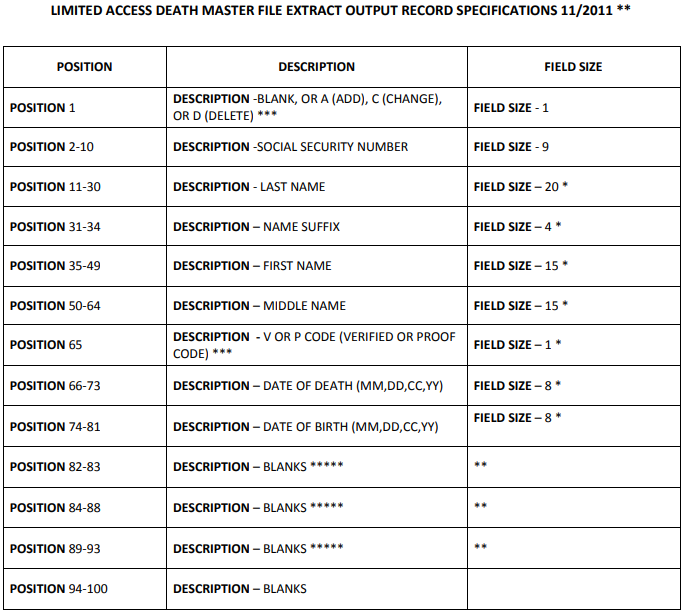
Sample records of the actual file:
001010001MUZZEY GRACE 1200197504161902
001010009SMITH ROGER 0400196902041892
001010010HAMMOND KENNETH 0300197604241904
001010011DREW LEON R V0830198706141908
CSV Converter
Converting the file from its proprietary format into CSV is necessary for for proper indexing by our search engine and for other uses cases such as opening it manually in Excel (setting aside the size of the file).
We have published the code as open source here: github.com/IntelligenceX/DeathMasterFile2CSV
This is the result of the above records in CSV:
Type,Social Security Number,Last Name,Name Suffix,First Name,Middle Name,Verified,Date of Death,Date of Birth,Blank 1,Blank2,Blank 3,Blank 4
,001010001,Muzzey,,Grace,,,1975-12-00,1902-04-16,,,,
,001010009,Smith,,Roger,,,1969-04-00,1892-02-04,,,,
,001010010,Hammond,,Kenneth,,,1976-03-00,1904-04-24,,,,
,001010011,Drew,,Leon,R,Verified,1987-08-30,1908-06-14,,,,
One of the few things we had to decide was the date format. Internally we are always using “YYYY-MM-DD” and googling for the answer, confirmed our choice, according to Stackoverflow:

Another choice we made was to camel-case the names (“MUZZEY GRACE” becomes “Muzzey Grace”) to improve human readability.
The converter reads 100 MB chunks at a time and processes it, as the input file (2011 version) is 8 GB of size. It took 5 minutes to convert its 85,822,194 records to CSV. The resulting CSV file is only 4.6 GB of size, since unnecessary white spaces are removed.
The 2013 version has 87,735,016 records and is 8.3 GB big. The converted CSV file is 4.7 GB big.