Want to investigate the Russian government? We are helping.
We just released a new search category “Government: Russia”. It indexes data from Russian governmental domains, including:
- *.gov.ru – Russian Government
- *.mil.ru – Ministry of Defence of the Russian Federation
- kremlin.ru – Official website of the President of Russia
- fsb.ru – Federal Security Service
- government.ru – Russian Government
- supcourt.ru – Supreme Court of Russia
- cikrf.ru – Central Election Commission of Russia
- ombudsmanrf.org – High Commissioner for Human Rights in the Russian Federation
The historical data goes back until December 2017. That means you can go back in time and get the content of Russian governmental websites up to that point using Intelligence X.
The index contains websites, office documents such as Word files and PDF files, pictures and others. The entire dataset is 3.4 TB big and increases every day, as the crawler make daily copies. It contains 451,172,519 selectors (such as URLs, domains, email addresses, IPs, etc.) and 17,934,098 items (= unique search results).
The data is available for free on intelx.io – you do not even need an account.
How to search the data
You can select the data category in the Advanced menu, to only search the Russian government data.
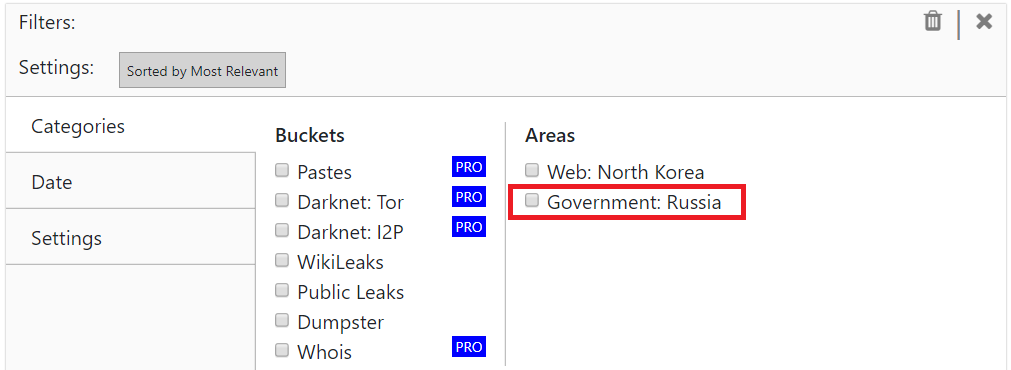
Here are real-life examples:
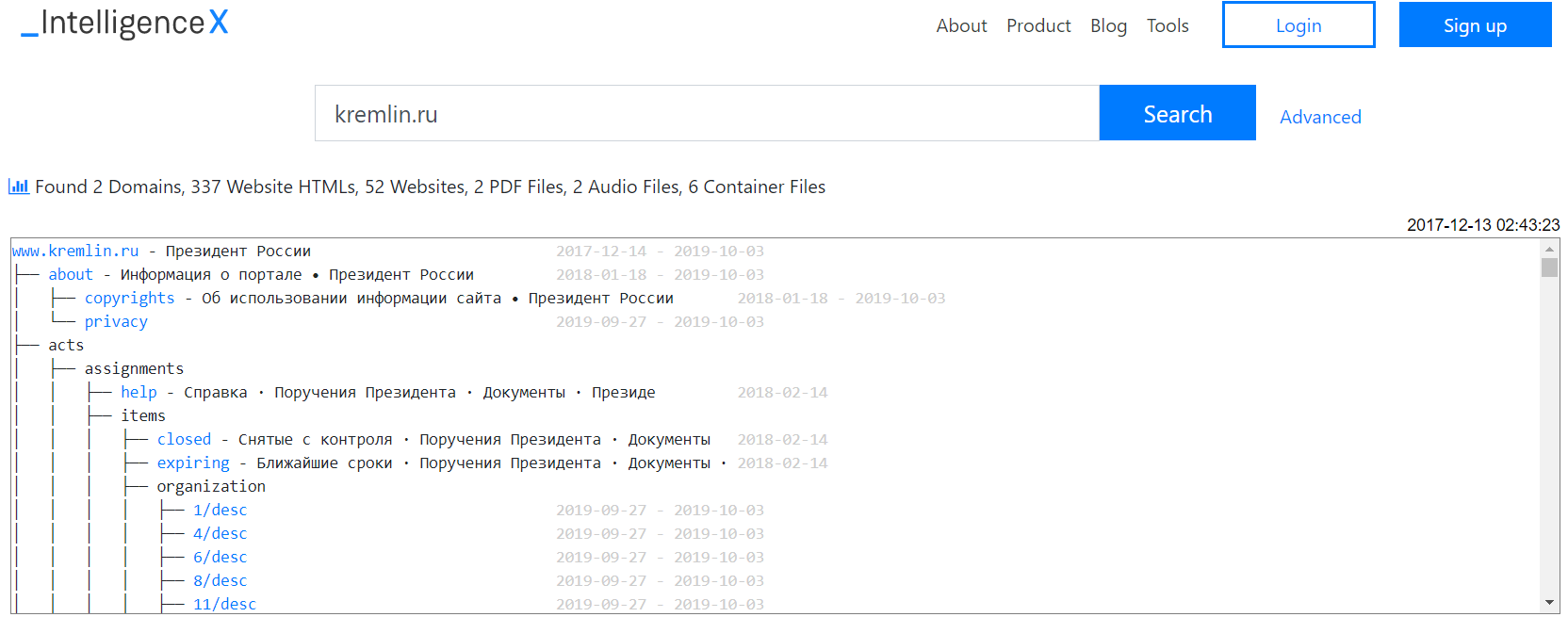
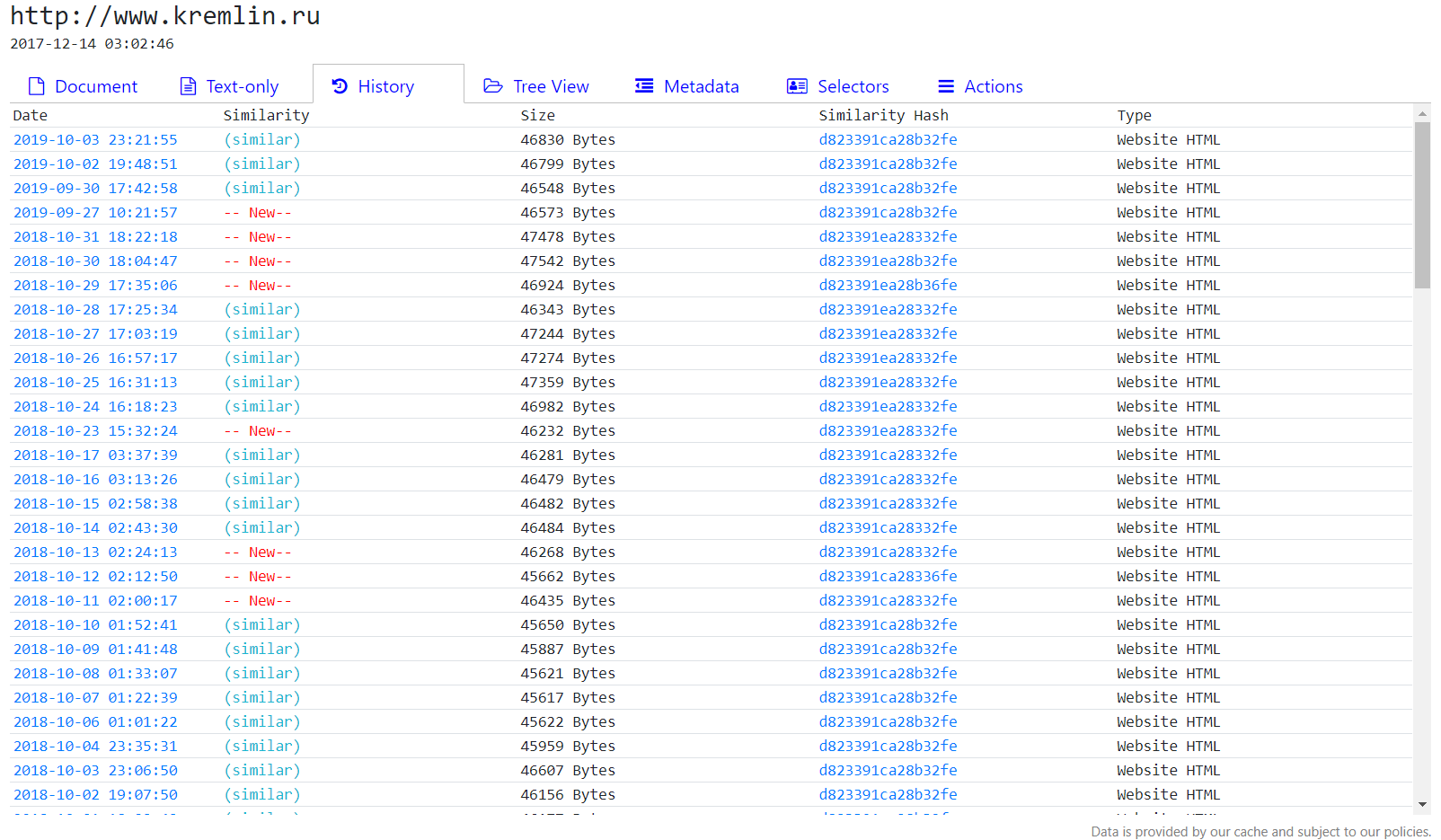
- Look at historical versions of kremlin.ru: intelx.io/?s=kremlin.ru&b=web.gov.ru&g=1 (this searches for “kremlin.ru” and enables “Group Smilar Results” under Settings)
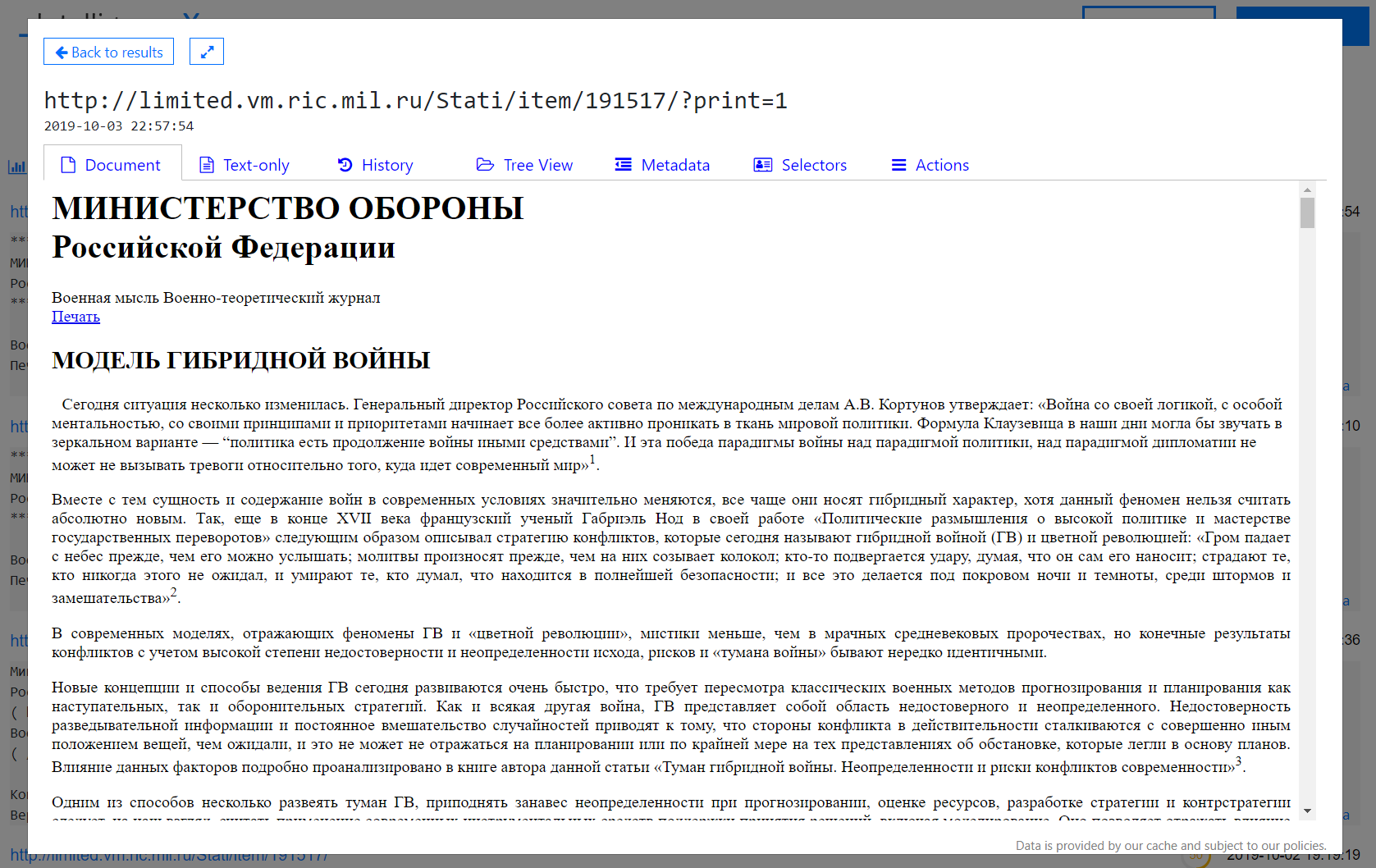
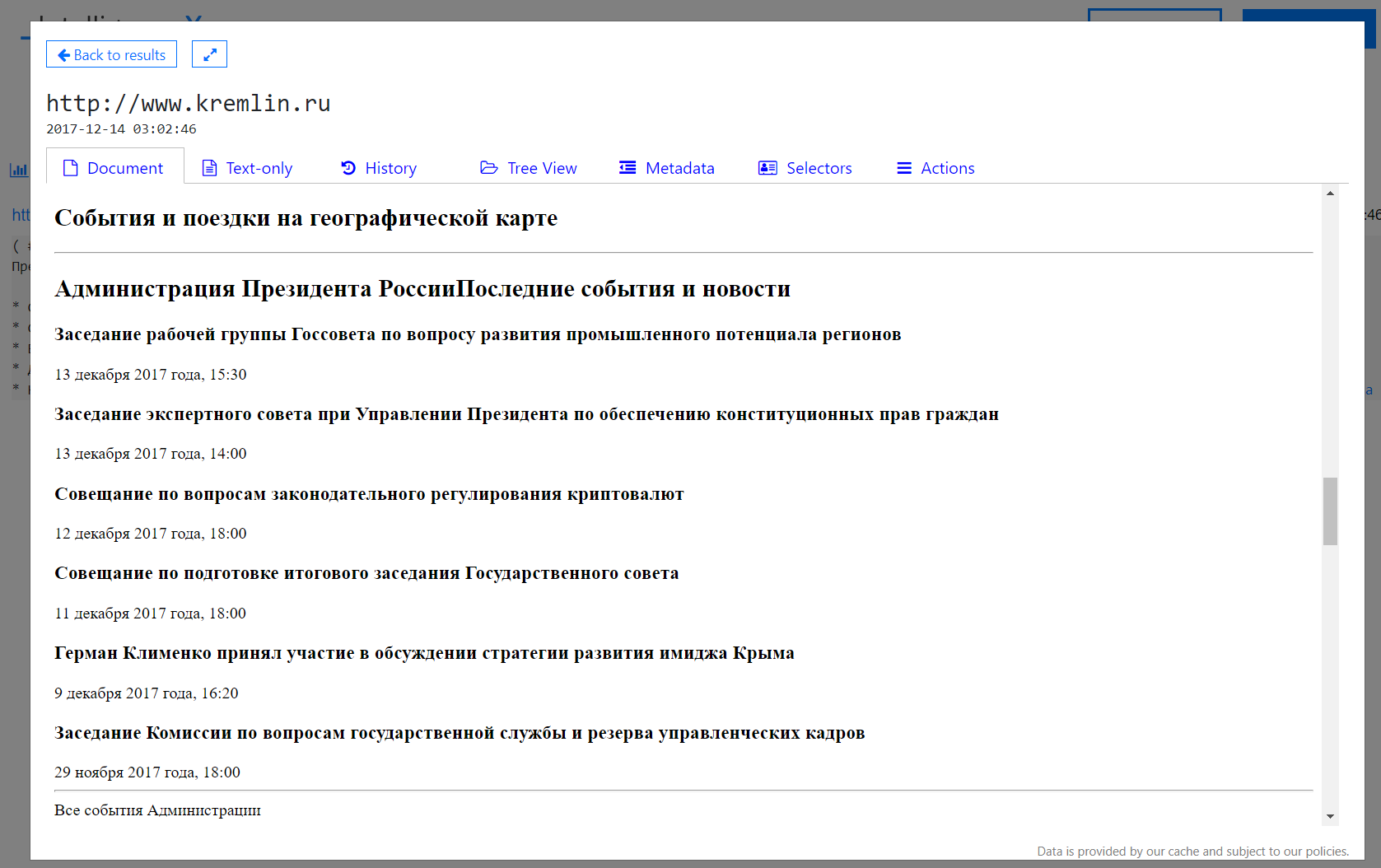
- You can click through and see the websites at the time and use the “History” tab to visit historical versions:
- List email addresses known for fsb.ru: intelx.io/?s=fsb.ru&b=web.gov.ru&pb=1 (this uses the Phonebook feature, enabled also in Settings)
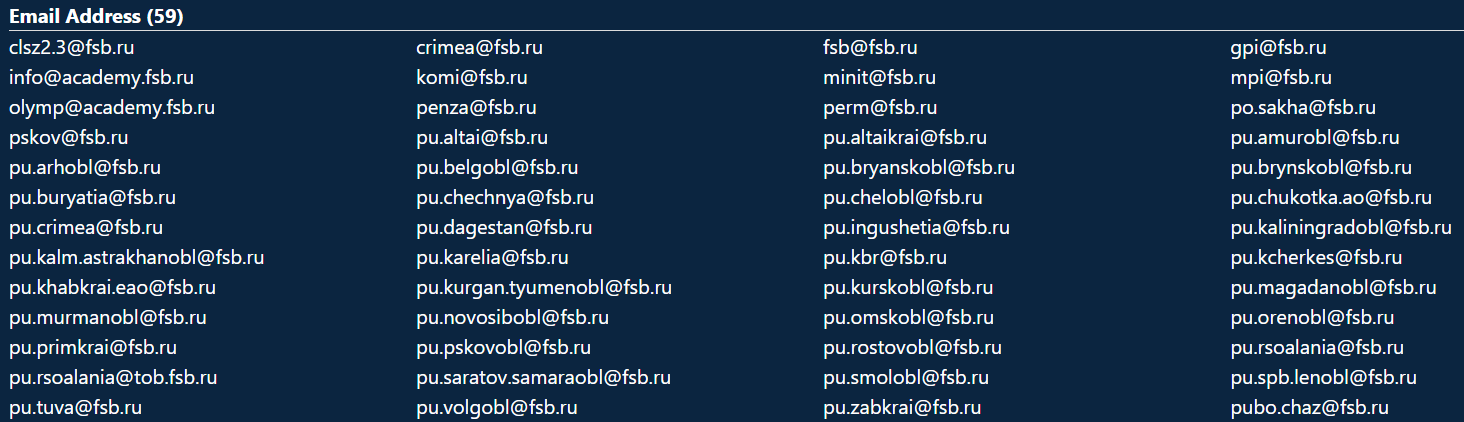
Note: There are even more fsb.ru email addresses known if you search all data across Intelligence X.
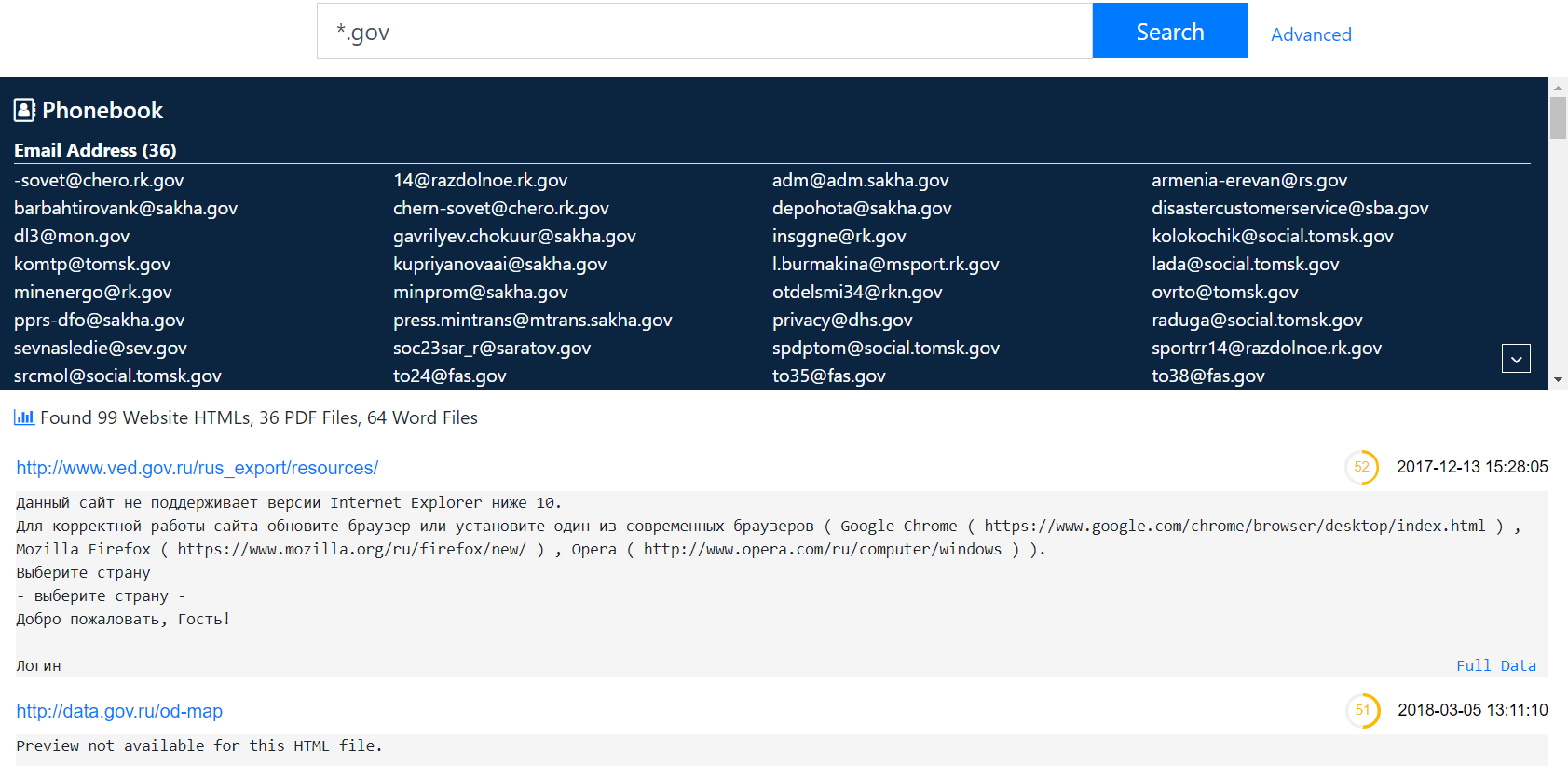
- Search for any mention of “.gov” domain names, email addresses or URLs on any Russian governmental website and list the results: intelx.io/?s=*.gov&b=web.gov.ru&pb=1&g=1
- Search for something specific. For example, a search for “defense.gov” lists 4 results: intelx.io/?s=defense.gov&b=web.gov.ru