WikiLeaks data in numbers
We have uploaded all the WikiLeaks data to Intelligence X and created a new category. You do not need an account or license to search through the WikiLeaks data using our site.
Try it out here! intelx.io/?s=cnn.com&b=leaks.public.wikileaks
Source & Challenges
Most of the raw data is available via file.wikileaks.org/file/ as well as torrents. There are a couple of organizational and technical challenges that come with the data:
- The files are mostly unstructured and there is no clear index.
- The published raw files do not always exactly match up in count with what’s published on wikileaks.org.
- The chaotic way of how and what is published in raw form likely represents the chaos within the WikiLeaks organization (see Conway’s Law).
- The file types vary. Some document are in PDF form, Word files (DOC, DOCX), some in picture form (JPG), and some in picture form embedded in PDFs. This makes it tricky to extract reliable meta-data (such as the title, creation date) and the data itself (the text).
- Spam: Sometimes the data contains pure spam. A human is required to go through each folder and decide whether the data may be of interest or not.
- Some data is compressed (7Z, RAR, ZIP) with many sub-files and folders.
- Fake news: Some data contains fake information (for example: Fake medical report about Steve Jobs having a HIV+ diagnosis).
- Pornographic content: Some attachments of emails contain pornographic content.
- Duplicates: Some files are duplicated.
- Extreme violence.
Counting the Input
- Count of files: 43,374
- Count of folders: 4,423
- Total size: 28.3 GB
Intelligence X Statistics
The Intelligence X statistics list more files than the input, because the compressed files (ZIP and other) contain many files that are extracted and stored separately.
- Count of items: 5,664,971
- Count of unique selectors: 368,818
- Count of total extracted selectors: 41,213,169
- Size of data files (total): 471 GB
The above statistics mean that we have 368,818 different search terms (selectors, like domain name, email address, etc.) that search in 5,664,971 results.
Out of the 368k unique selectors, most are – not surprisingly – email addresses with 46%. Next is Credit Cards with 19% followed by URLs 15%.
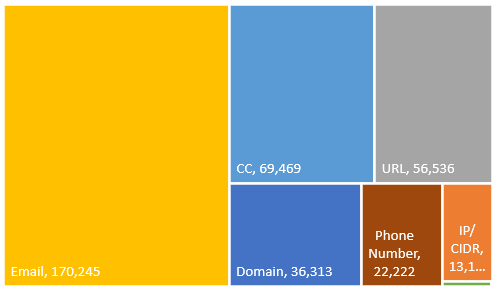
Selector breakdown for the WikiLeaks data
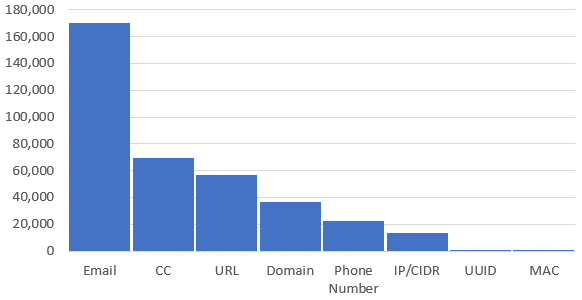
Same data, different visualization
Cryptome
Update 8/9/2019: We uploaded the Cryptome data into the WikiLeaks bucket.
- Count of items: 93,234
- Count of unique selectors: 333,122
- Count of total extracted selectors: 539,908
- Size of data files (total): 39 GB