A comparison of darknet search engines
A few days ago a new search engine DarkSearch for Tor launched, adding to the mix of other existing search engines out there like Ahmia, Torch, Not Evil, and Haystack – it’s time for a feature comparison!
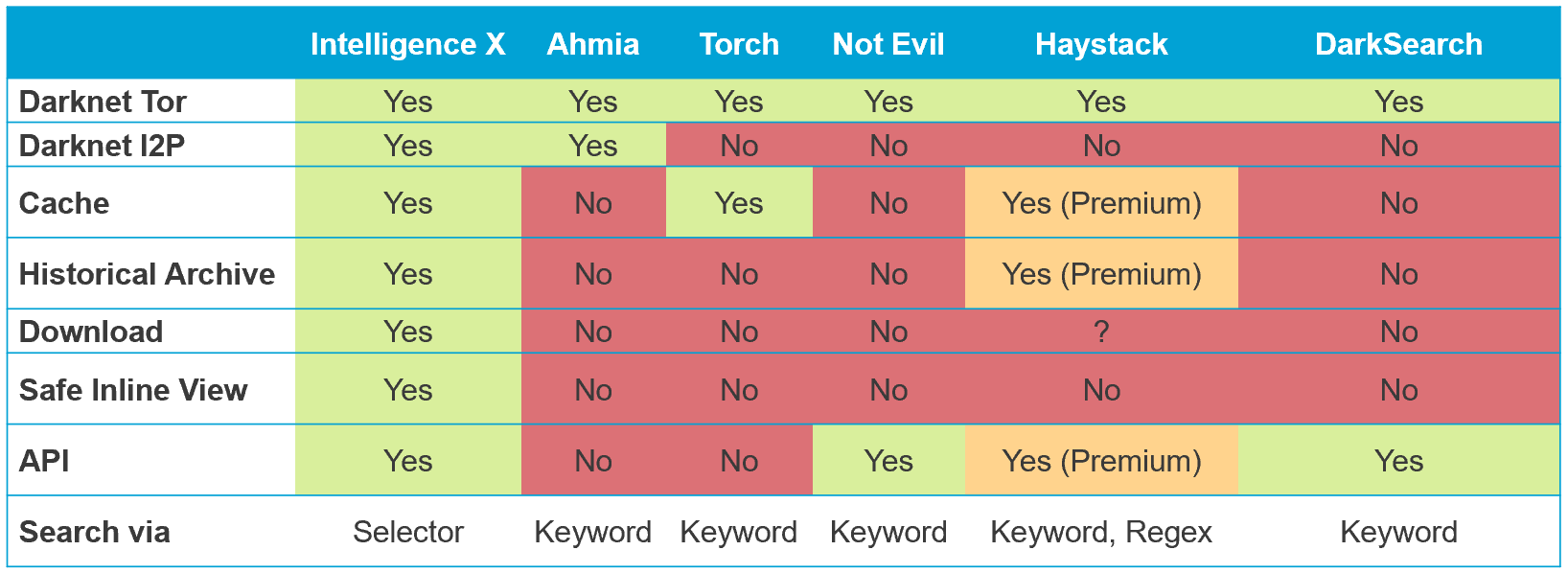
No search engine can cover 100% of the pages due to the nature of Tor. There is no central .onion repository so the first challenge is to find the .onion links. Other challenges when running a search engine include data size (and associated storage and processing power), data formats, and many smaller challenges like depth of crawling (i.e. how many sub-pages, how to behave when there are infinite sup-pages).
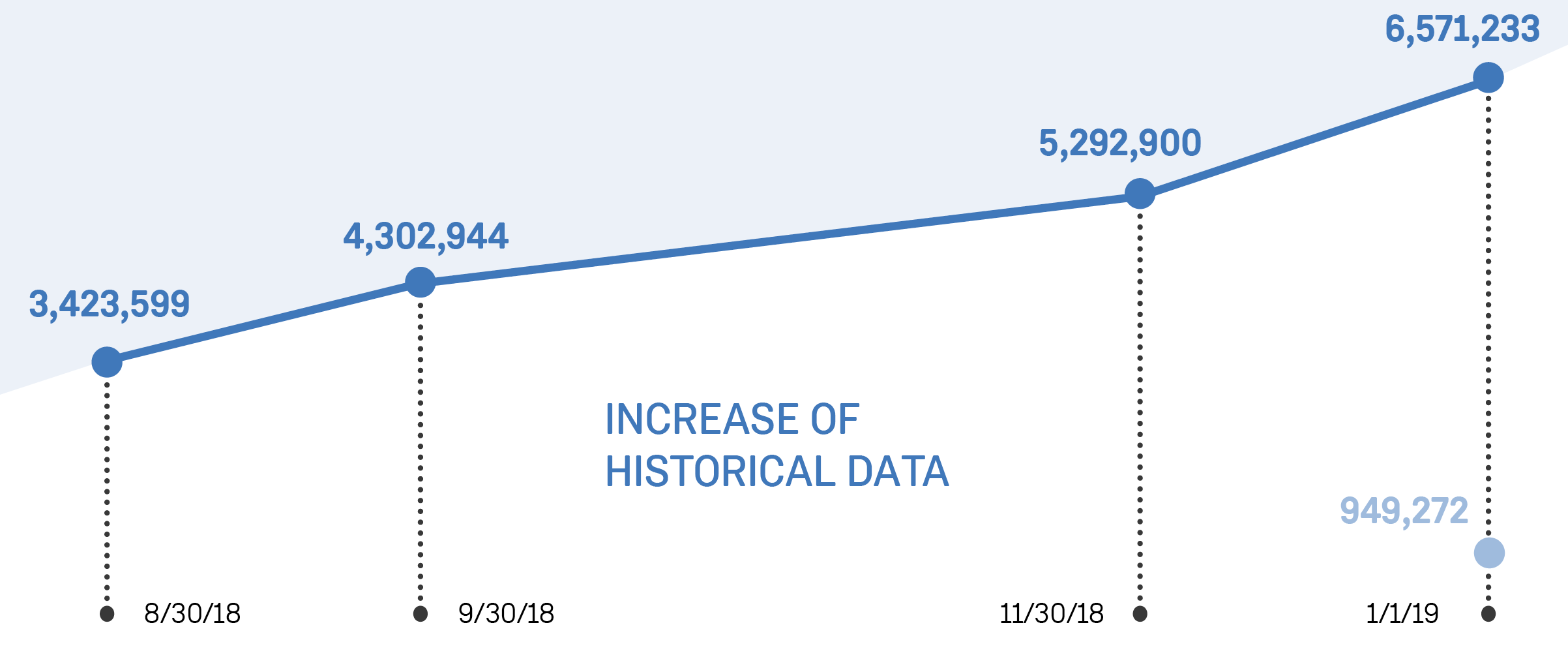
Items indexed by Intelligence X
The following graph shows our index of Tor (dark blue) and I2P (light blue). As of April 2019, we have 10,197,379 items indexed for Tor and 1,557,915 items for I2P. An item can be any supported file format – including HTML, text, PDF, office documents (Word, Excel, and PowerPoint files), and since yesterday, even eBooks.
We have 2,250,020 .onion addresses in our index, although only a small fraction is actually active. For I2P our index has 3,565 .i2p domains listed.