We just added native support to Intelligence X for the following data formats:
Native support means end-to-end support. This ranges from indexing and crawling files of various data sources, to processing them internally and presenting them to the end-user on the frontend intelx.io. Indexing is the process of taking a file, reading it, and extracting any text thus making it searchable.
intelx.io shows text preview in the results and supports inline view. This means that it immediately shows the text of a document in a detailed view (when you click on a result) without forcing the user to leave the website or download the file locally.
Inline view of office documents is a convenient feature, but also has an important security aspect: if the end-user downloads and opens unknown office documents (especially from the darknet), there is a risk of malicious embedded VBA macros and other exploits.
Intelligence X now natively supports all major office formats: Word, Excel, PowerPoint, and PDF.
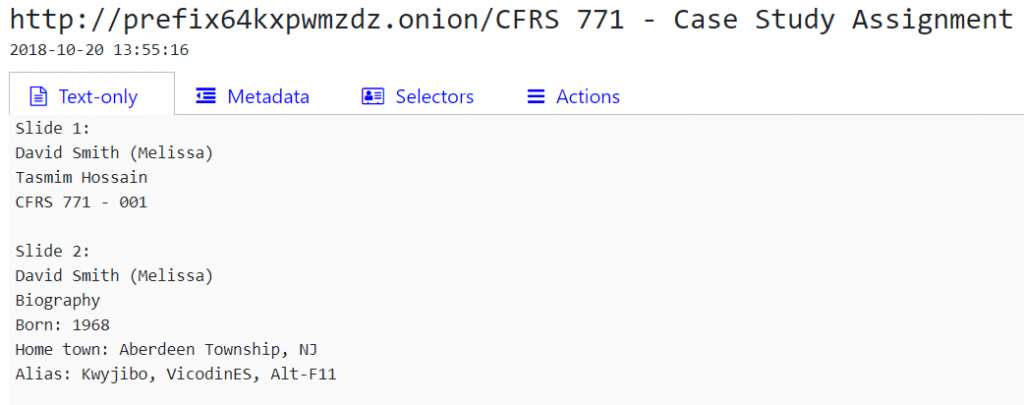
Before, a PowerPoint file was displayed in the detailed view as “data salad” 🥗:
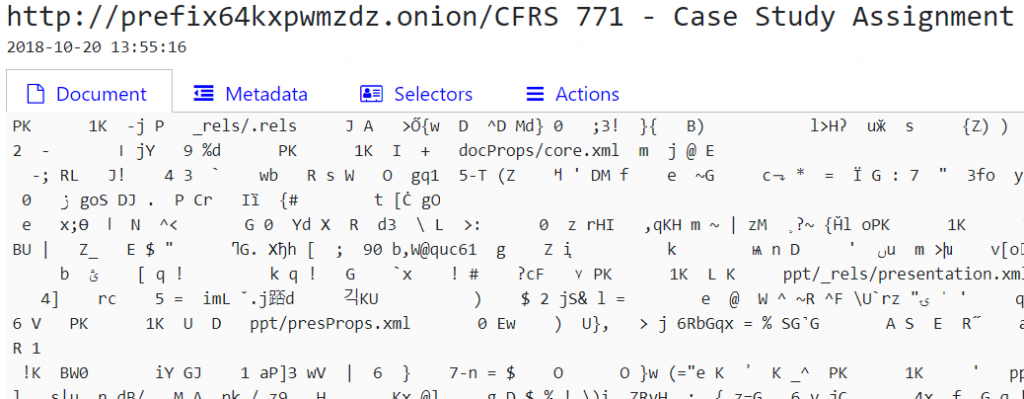
Now, you can see the text of the presentation (both in the preview and detailed view):