A new type of HTTP client attacks is around the corner, and it’s really sneaky
Google is working on a new feature called “Signed HTTP Exchanges (SGX)” (note: Google also abbreviates it as “SXG”). According to their website:
Signed HTTP Exchanges (SGX), part of an emerging technology called Web Packages is now available in Chrome 73. A Signed HTTP Exchange makes it possible to create “portable” content that can be delivered by other parties, and this is the key aspect, it retains the integrity and attribution of the original site.
The IPFS project discusses using that technology in this GitHub issue. They quote Mozilla with the following statement:
Mozilla has concerns about the shift in the web security model required for handling web-packaged information. Specifically, the ability for an origin to act on behalf of another without a client ever contacting the authoritative server is worrisome, as is the removal of a guarantee of confidentiality from the web security model (the host serving the web package has access to plain text). We recognise that the use cases satisfied by web packaging are useful, and would be likely to support an approach that enabled such use cases so long as the foregoing concerns could be addressed.
tl;dr
This new technology is likely going to result in new types and new ways of attacks. By combining old versions of parts of websites, an attacker could potentially locally inject malicious JS or CSS code into websites. That could be used for phishing, stealing cookies, or other activities like serving as gateway for JavaScript based banking trojans (via Automatic Transfer Systems) or credit card stealers. See below “poisoning 3rd party libraries” for details.
The problem with Web Packages
Mozilla hits the nail on its head with their concern. Once you introduce web packages that can be supplied by (potentially evil minded) 3rd parties, all kind of bad things may happen:
- Replay attacks. Just like with every P2P network there are potentially replay attacks, in which an attacker uses a historically captured packet and re-sends it. There are mitigations available, typically by using dates and version number in packets. With web packages you can (potentially even selectively) “replay” (supply) old versions of the website or parts of it, which leads to the next problem:
- Local cache poisoning using the replay attack to inject old vulnerable parts (like JavaScript) of a website into the cache and then exploit them.
To realize such an attack, an attacker would first create at least daily copies of provided web packages of a target (of course, assuming that the target supports web packages).
Then, once a vulnerable version is identified (even if years have passed between collecting the web package and identifying its vulnerable) the attacker can weaponize it. The attacker can even try to artificially put different pieces of a website together to achieve a certain outcome.
What about protections, cache verification and expiration?
There is information here that talks about caching (emphasis added):
When fetching a resource (
https://distributor.example.org/foo.sxg) with theapplication/signed-exchangeMIME type, the UA parses it, checks its signatures, and then if all is well, redirects to its request URL (https://publisher.example.org/foo) with a “stashed” exchange attached to the request. The redirect applies all the usual processing, and then when it would normally check for an HTTP cache hit, it also checks whether the stashed request matches the redirected request and which of the stashed exchange or HTTP cache contents is newer. If the stashed exchange matches and is newer, the UA returns the stashed response.
As written above, the browser shall check the HTTP cache to see if there is a newer result than the provided SXG resource. This works, of course, onlyin the case that the user already visited the target site serving a newer version (than the SXG). Users that never visited the site, or that are opening the web package in a private browser window, will still be vulnerable.
The actual protection against this type of attack is to use the “expiration time” field of the signature header and set it to a relatively low future date.
In addition, web servers should use the server side “Cache-Control” and “Expires” headers to make sure the browsers can use it for the comparison, whether or not an HTTP cache hit is newer than the provided SXG.
Poisoning 3rd party libraries
The fun thing with this attack is that the target website does NOT even have to support web packages; if a linked web server (for example, for a JavaScript file) supports it, then the responses of that 3rd party server can be used for replay attacks to poison the cache and affect the original target.
Full example:
- Let’s assume our target “centralbank.com” uses jQuery hosted on
https://code.jquery.com/jquery-latest.min.js - Let’s assume jquery.com decides to turn on support for web packages. An attacker will now start making daily copies of the SXG files.
- At a later point in time, the jQuery developers recognize that there is a vulnerability and they update it.
- However, because the attacker is now aware that the old version is vulnerable, he can set up a malicious site that provides the old vulnerable version, and then redirect the user to centralbank.com.
- Once the user visits centralbank.com, it may use the old (vulnerable) cached version that the attacker may be able to exploit.
To be even more evil: What if the remotely hosted jQuery JavaScript file references another domain, and then the developers decide to change that domain?
What if, for example, https://code.jquery.com/jquery-latest.min.js would (hypothetically) reference “jqueryupdate.com” and the developers decide to streamline their operations to use “update.jquery.com” instead, and abandon the old one? In the future an attacker can register jqueryupdate.com and supply the old JS file via SXG. It would allow the attacker to locally inject arbitrary JS code into any website that reference this jQuery file.
More attacks based on this will follow
There are more attacks possible similar to the one described with poisoning 3rd party libraries.
An attacker could create daily SXG copies of a target (hypothetically) like nytimes.com, and then wait until any of the referenced domains (for including external JavaScript) becomes available.
Once that domain becomes available, let’s say the “optimizely.com” in the below example, an attacker can register it, get a certificate, upload a malicious JavaScript, and create their own SXG file of an arbitrary (malicious) JavaScript file.
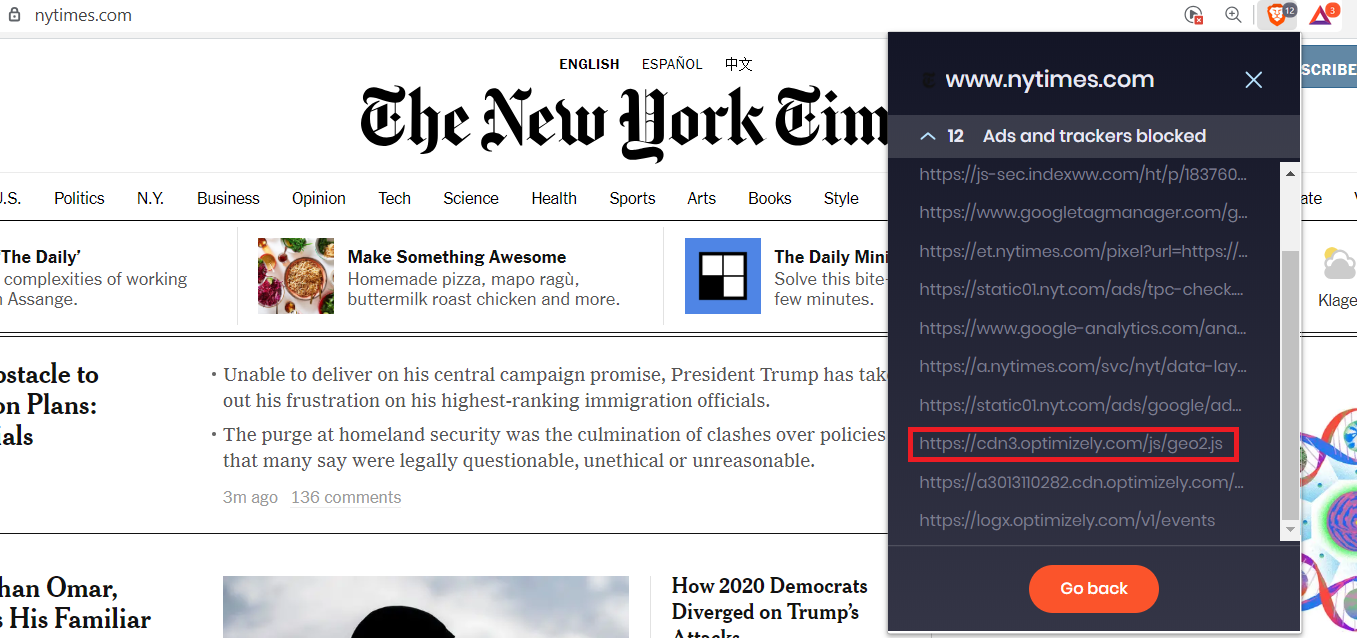
By having a legitimate historical SXG copy, plus a future SXG copy of a referenced resource, the attacker can deploy arbitrary JavaScript code, that could for example steal the session cookie and send it to a remote server.
The attacker could package up these SXG into a single website and send it via email or share the link via social media.
As stated before, the only real protection against this is setting strict cache expiration and signature expiration time settings.